隨著全球?qū)稍偕茉葱枨蟮娜找嬖鲩L,生物質(zhì)能作為一種重要的清潔能源,其開發(fā)與利用受到廣泛關(guān)注。高效、可靠的生物質(zhì)能資源數(shù)據(jù)庫信息系統(tǒng)對于資源評估、項目規(guī)劃與管理至關(guān)重要。在這一背景下,引入現(xiàn)代化的數(shù)據(jù)處理與集成技術(shù)成為必然選擇。Apache Kafka作為一個高吞吐量、可水平擴展的分布式消息系統(tǒng),為構(gòu)建健壯、實時的生物質(zhì)能數(shù)據(jù)管道提供了強有力的支持。
一、生物質(zhì)能資源數(shù)據(jù)庫信息系統(tǒng)的挑戰(zhàn)
生物質(zhì)能資源數(shù)據(jù)具有來源多樣、格式異構(gòu)、數(shù)據(jù)量大且產(chǎn)生速度快的特點。數(shù)據(jù)可能來自衛(wèi)星遙感、氣象站、地面?zhèn)鞲衅鳌嶒炇曳治鰣蟾嬉约叭斯ふ{(diào)查記錄等。傳統(tǒng)的中心化數(shù)據(jù)庫系統(tǒng)在處理此類實時、流式數(shù)據(jù)時,往往面臨以下挑戰(zhàn):
- 數(shù)據(jù)集成復(fù)雜:不同來源的數(shù)據(jù)格式和協(xié)議各異,整合難度大。
- 實時性要求高:資源存量、分布及物化特性需要近乎實時的監(jiān)控與分析。
- 系統(tǒng)可擴展性差:隨著監(jiān)測點增多和數(shù)據(jù)粒度細(xì)化,傳統(tǒng)架構(gòu)難以線性擴展。
- 數(shù)據(jù)可靠性需求:關(guān)鍵數(shù)據(jù)在傳輸與處理過程中不容丟失。
二、Kafka的核心優(yōu)勢與架構(gòu)
Apache Kafka是一個分布式流處理平臺,其核心是一個高吞吐量的發(fā)布-訂閱消息系統(tǒng)。它通過以下特性應(yīng)對上述挑戰(zhàn):
- 高吞吐與低延遲:Kafka能夠輕松處理每秒數(shù)百萬條消息,滿足海量生物質(zhì)能數(shù)據(jù)實時接入的需求。
- 持久化與可靠性:所有消息被持久化到磁盤并支持多副本冗余,確保數(shù)據(jù)不會丟失。
- 水平可擴展性:Kafka集群可以通過增加節(jié)點來無縫擴展存儲容量和處理能力。
- 流數(shù)據(jù)處理:與Kafka Streams或KsqlDB等流處理庫結(jié)合,支持對數(shù)據(jù)進(jìn)行實時轉(zhuǎn)換、聚合和分析。
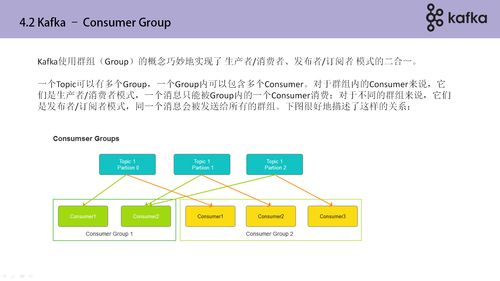
在架構(gòu)上,Kafka采用主題(Topic)對消息進(jìn)行分類。生產(chǎn)者(Producer)將各類生物質(zhì)能數(shù)據(jù)(如秸稈產(chǎn)量、熱值數(shù)據(jù)、地理位置信息)發(fā)布到特定主題,而消費者(Consumer)則可以訂閱這些主題,實時消費數(shù)據(jù)并寫入下游系統(tǒng),如資源數(shù)據(jù)庫、實時分析儀表板或機器學(xué)習(xí)模型。
三、Kafka在生物質(zhì)能信息系統(tǒng)中的典型應(yīng)用場景
1. 實時數(shù)據(jù)采集與聚合:
遍布各地的物聯(lián)網(wǎng)傳感器可以實時上報生物質(zhì)原料的濕度、存量、地理位置等信息。這些數(shù)據(jù)通過輕量級代理(如MQTT)橋接至Kafka主題,形成一個統(tǒng)一的數(shù)據(jù)流總線。下游的數(shù)據(jù)處理應(yīng)用可以訂閱這些主題,進(jìn)行實時清洗、格式標(biāo)準(zhǔn)化,并聚合到中心資源數(shù)據(jù)庫中,為決策提供即時視圖。
2. 系統(tǒng)解耦與可靠數(shù)據(jù)傳輸:
生物質(zhì)能信息系統(tǒng)通常包含多個子系統(tǒng),如資源評估系統(tǒng)、物流調(diào)度系統(tǒng)、能源轉(zhuǎn)化監(jiān)控系統(tǒng)。Kafka作為中間件,可以解耦這些系統(tǒng)間的直接依賴。例如,資源評估系統(tǒng)產(chǎn)生的新的資源分布圖數(shù)據(jù),只需發(fā)布到“resource-map-update”主題,物流系統(tǒng)作為消費者獨立訂閱,按自身節(jié)奏消費,即使物流系統(tǒng)臨時停機,數(shù)據(jù)也不會丟失,重啟后可以繼續(xù)處理。這極大提升了整個系統(tǒng)的彈性和可維護(hù)性。
3. 流式分析與實時監(jiān)控:
利用Kafka Streams或Flink等流處理框架,可以直接在數(shù)據(jù)流上進(jìn)行實時計算。例如,實時計算某一區(qū)域內(nèi)生物質(zhì)原料的收集速率與預(yù)測消耗速率,動態(tài)預(yù)警資源短缺風(fēng)險;或者實時分析生物質(zhì)電廠入爐原料的特性數(shù)據(jù),優(yōu)化燃燒控制參數(shù)。這些實時洞察能夠顯著提升運營效率。
4. 歷史數(shù)據(jù)回放與事件溯源:
Kafka的消息持久化特性使得它能夠長期存儲數(shù)據(jù)流。這對于生物質(zhì)能研究至關(guān)重要。研究人員可以“回放”過去某一時間段(如整個作物生長季)的所有環(huán)境與資源數(shù)據(jù)流,用于模型校準(zhǔn)、趨勢分析或事故復(fù)盤,實現(xiàn)了完整的事件溯源。
四、實施架構(gòu)示例
一個基于Kafka的生物質(zhì)能資源數(shù)據(jù)平臺參考架構(gòu)如下:
[數(shù)據(jù)源] -> [Kafka生產(chǎn)者/連接器] -> [Apache Kafka集群]
|
v
[流處理層: Kafka Streams / Flink] -> [實時儀表板]
|
v
[消費者應(yīng)用群]
/ | \
/ | \
[資源主數(shù)據(jù)庫] [GIS系統(tǒng)] [預(yù)測模型]在此架構(gòu)中,Kafka集群是中樞神經(jīng),負(fù)責(zé)承接所有數(shù)據(jù)流并可靠地分發(fā)給各個需要的業(yè)務(wù)系統(tǒng),實現(xiàn)了數(shù)據(jù)流的統(tǒng)一管理和按需分發(fā)。
五、結(jié)論
將Kafka分布式消息系統(tǒng)引入生物質(zhì)能資源數(shù)據(jù)庫信息系統(tǒng),能夠有效解決多源異構(gòu)數(shù)據(jù)實時集成、系統(tǒng)高并發(fā)訪問及模塊解耦等核心問題。它構(gòu)建了一個高可靠、可擴展的數(shù)據(jù)流通基石,使得生物質(zhì)能數(shù)據(jù)的采集、傳輸、處理和分析變得更加高效和靈活。這不僅提升了資源管理的精細(xì)化水平和響應(yīng)速度,也為基于數(shù)據(jù)的智能決策和自動化運營奠定了堅實基礎(chǔ),是推動生物質(zhì)能產(chǎn)業(yè)數(shù)字化、智能化升級的關(guān)鍵技術(shù)組件之一。